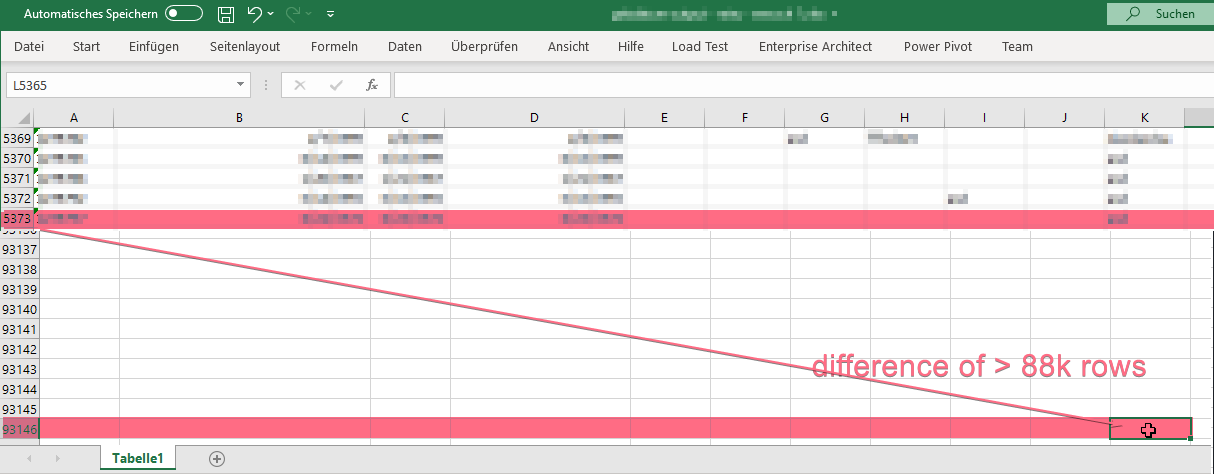
I had the weird situation, that an Excel source at a SSIS job did produce almost 100k output rows whereas the read Excel sheet did only contain around 5k rows of data. After dissecting the results of enabled Data Viewers I found out that the XLSX documents seems to have some internal metadata which also keeps a pointer to the last data cell. Or at least what Excel thinks what this last cell might be. This pointer however, can be read and interpreted (for a number of valid reasons) which would lead to the behaviour I observed.
Deleting all seemingly empty rows did not do the trick, so I consulted Google which lead me to the following knowledge article which finally cleared everything up (literally): https://support.office.com/en-us/article/Locate-and-reset-the-last-cell-on-a-worksheet-C9E468A8-0FC3-4F69-8038-B3C1D86E99E9
TL;DR;
Pressing CTRL + END directly jumps the the last populated cell according to Excels internal pointer. In order to reset this, select all the rows or, even easier when applicable in your situtation, select the whole sheet, and finally clear the (visual) formattings. Done.
Oh, for the case your are also a curious one: I peeked into the XLSX file (which is an ordinary ZIP archive if you didnt know) and found the internal “pointer” I was suspecting. Inside the sheet XML files which are located under /xl/worksheets directory, there is a <dimensions ref="A1:D93146"/> right as first child element under the <worksheet/> root element that holds the misleading information. 😉