Using Azure Logic Apps for any sorts of workflow automation or process orchestration is quite comfortable and easy, especially since almost any HTTP-related task consists of nothing more than adding some action steps to the execution flow.
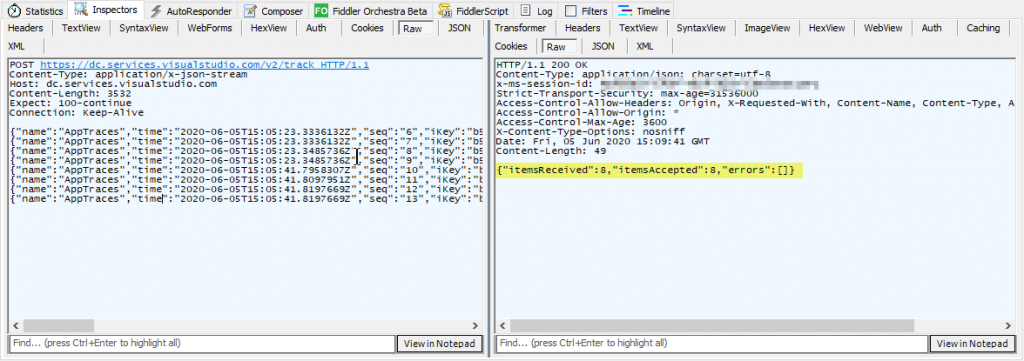
But have you ever had a closer look to the actual HTTP request data which is finally sent over the wire in the background by the Logic App engine? You would be surprised what additional informations (=metadata) are automatically included to the final HTTP request. Let’s have a look on an example.
I just created an empty Logic App and added an HTTP action calling test endpoint over at Pipedream. Then I did manually invoke it using the Run command. Just ignore the BadRequest error response, it doesn’t matter here.
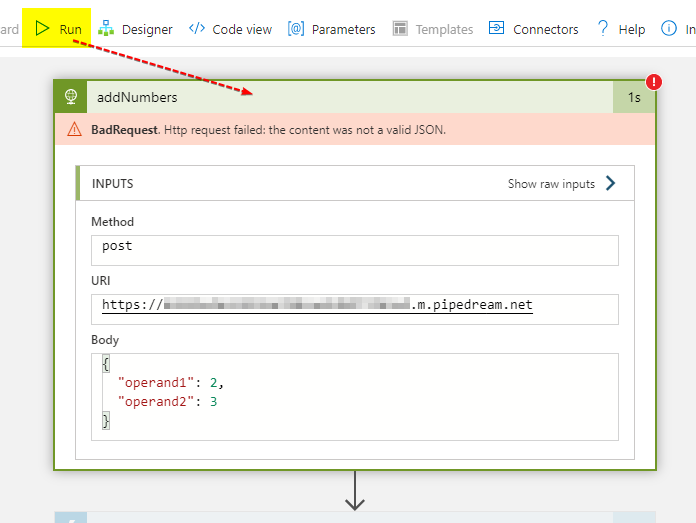
The final HTTP request sent by the Logic App engine over the wire then looks like this:
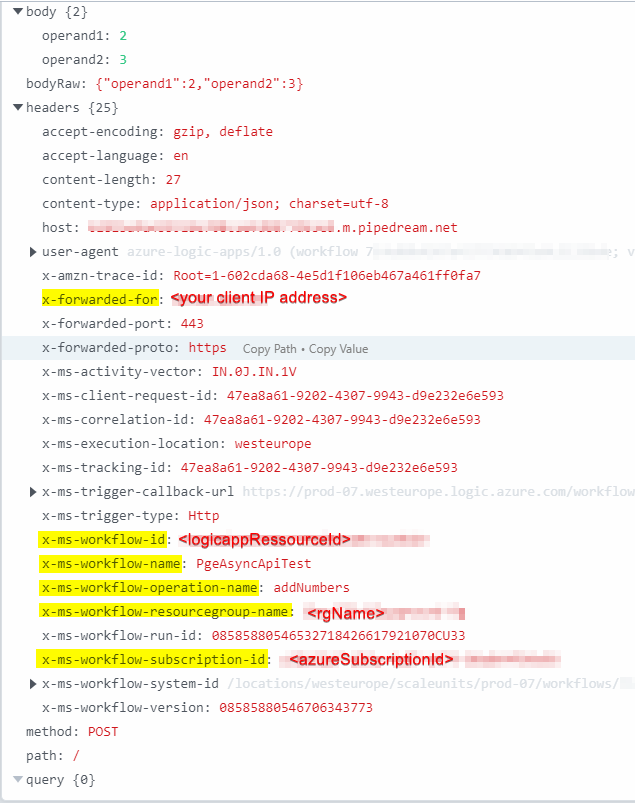
As you can see, there are a lot of platform-internal and informations leaking through to the receiving party. Including sensible informations like
- the client machines IP address from which the Logic App execution was triggered from
- the Azure subscription id
- the Logic App ressource id, the ressource group name in which it is contained in
- the Logic App’s name as well the name of the HTTP action that caused the HTTP request
While this kind of (unencrypted) metadata exchange might be very helpful or even required in certain Azure solution scenarios, it must be assured that this happens in a secure environment where every receiving party is trusted. However, this is NOT the case when HTTP requests are going out to any external service which is operated by a 3rd party.
Conclusion
When using HTTP actions in Logic Apps, ask yourself if the receiving party is trustworthy and if the information leakage via proprietary HTTP headers shown above is tolerable. Otherwise, make sure to filter out the questionable X-* headers from the resulting request using for example a proxy service or specifiying outgoing policies on an Azure API Management ressource.